Published: 2026-06-13
SQL Server ↔ PostgreSQL Data Type Mapping: The Complete Reference (Both Directions)
When you migrate between SQL Server and PostgreSQL, the first thing you hit is the type system. bit isn't boolean. nvarchar has no Postgres twin. datetime2, datetimeoffset, uniqueidentifier, money, rowversion — each needs a deliberate decision. This is the exact mapping Jam SQL Studio uses when it migrates a table or runs a cross-engine schema compare, documented in both directions, including the lossy edges most cheat-sheets skip. It's not a generic table copied from a wiki — every row here is what the tool actually emits.
The trick: route everything through a canonical type
Jam SQL Studio doesn't keep an N×N grid of "MSSQL type X → Postgres type Y" rules. Instead, every engine defines two functions against a single canonical type model: toCanonical (native type → canonical) and fromCanonical (canonical → native). A migration is just source.toCanonical → CanonicalType → target.fromCanonical.
The canonical kinds are deliberately small and engine-neutral: boolean, sized integers (int8/int16/int32/int64), decimal, float32/float64, char/varchar/text, binary/varbinary/blob, uuid, date/time/timestamp/timestamptz, json, and unknown for everything with no faithful cross-engine equivalent. Because the hub is symmetric, the mapping works for any pair — SQL Server, PostgreSQL, MySQL, Oracle, SQLite — not just this one. This page focuses on the MSSQL↔Postgres pair because it's the most common cross-engine move.
SQL Server → PostgreSQL
What each SQL Server type becomes when you migrate to PostgreSQL:
| SQL Server type | PostgreSQL type | Notes |
|---|---|---|
bit | boolean | 0/1 coerced to FALSE/TRUE |
tinyint | smallint | widened — Postgres has no 1-byte integer |
smallint | smallint | |
int | integer | |
bigint | bigint | |
real | real | single precision |
float | double precision | |
decimal(p,s) / numeric(p,s) | numeric(p,s) | precision/scale preserved |
money | numeric(19,4) | lossy: money spelling dropped |
smallmoney | numeric(10,4) | |
char(n) / nchar(n) | character(n) | N-type byte width → char count |
varchar(n) / nvarchar(n) | character varying(n) | |
varchar(max) / nvarchar(max) / text / ntext | text | unbounded character data |
uniqueidentifier | uuid | lossless both ways |
date | date | |
time(n) | time(n) | fractional-seconds precision preserved |
datetime2(n) | timestamp(n) | without time zone |
datetime | timestamp(3) | legacy fixed precision |
smalldatetime | timestamp(0) | minute precision |
datetimeoffset(n) | timestamp(n) with time zone | tz-aware on both sides |
binary(n) / varbinary(n) / image | bytea | length dropped; Postgres bytea is unbounded |
rowversion / timestamp | bytea | SQL Server timestamp is an 8-byte row-version, not temporal |
json (SQL Server 2025) | jsonb | |
xml, sql_variant, hierarchyid, geography, geometry, CLR/UDT | verbatim + warning | no canonical equivalent — review by hand |
PostgreSQL → SQL Server
Going the other way — what each PostgreSQL type becomes when you migrate to SQL Server. Note the standout: because every Postgres character type is Unicode (the database encoding, typically UTF-8), they come back as N-prefixed SQL Server types.
| PostgreSQL type | SQL Server type | Notes |
|---|---|---|
boolean | bit | TRUE/FALSE → 1/0 |
smallint / int2 | smallint | |
integer / int4 / serial | int | serial identity is not carried — warning |
bigint / int8 / bigserial | bigint | |
numeric(p,s) / decimal(p,s) | decimal(p,s) | precision/scale preserved |
money | decimal(19,2) | lossy: locale-scaled, money spelling dropped |
real / float4 | real | |
double precision / float8 | float | |
character(n) / char(n) | nchar(n) | Postgres char is Unicode → N-type |
character varying(n) / varchar(n) | nvarchar(n) | Unicode → N-type |
text | nvarchar(max) | idiomatic modern unbounded Unicode |
bytea | varbinary(max) | |
uuid | uniqueidentifier | |
date | date | |
time(n) | time(n) | |
time(n) with time zone / timetz | time(n) | lossy: tz dropped (no canonical timetz) |
timestamp(n) (without tz) | datetime2(n) | |
timestamp(n) with time zone / timestamptz | datetimeoffset(n) | |
json / jsonb | json | needs SQL Server 2025 native json on the target |
bit / bit varying | verbatim + warning | Postgres bit is a bit string, not a boolean |
arrays, ranges, inet/cidr, interval, hstore, tsvector, xml, enums | verbatim + warning | no canonical equivalent — review by hand |
The edge cases worth knowing
These are the conversions that surprise people — the ones a naive "find and replace the type name" approach gets wrong.
bitis not a boolean — in either engine the obvious-looking name is a trap. SQL Serverbitis a boolean (and maps to Postgresboolean), but PostgreSQLbit/bit varyingare bit strings. So Postgresbitdoes not map to SQL Serverbit— it's carried verbatim with a warning. Onlybooleanparticipates in the boolean mapping.- SQL Server
timestampis not a timestamp. It'srowversion— an 8-byte automatically-incrementing binary value, nothing to do with dates. It maps tobytea, not a temporal type. (This single naming collision causes more migration bugs than any other.) - Postgres character types return as N-types. Because Postgres stores character data in the database encoding (UTF-8), every
varchar/char/textis effectively Unicode — so migrating to SQL Server yieldsnvarchar/nchar/nvarchar(max), never the non-Unicode variants. tinyintwidens. Postgres has no 1-byte integer, sotinyintbecomessmallint. This round-trips tosmallint, not back totinyint— the only safe direction-stable choice.moneyalways loses its spelling. SQL Servermoney→numeric(19,4); Postgresmoney→decimal(19,2). The numeric precision is faithful, but neither side preserves themoneytype name or its locale formatting — which is usually what you want, sincemoney's locale behavior is a frequent source of bugs.jsonneeds a modern target. Nativejsonmapping assumes SQL Server 2025 (the first version with a nativejsoncolumn type). Migrating Postgresjsonbto an older SQL Server means storing it asnvarchar(max)instead — declare the column accordingly.
Values get coerced, not just types
A correct type mapping isn't enough — the stored values have to be valid literals in the target dialect too. When Jam SQL Studio copies rows it coerces them as it builds the INSERT:
- Booleans: SQL Server
bit0/1→ PostgresFALSE/TRUE(and back). - Binary: written as Postgres
byteahex literals ('\x…'). - Dates / timestamps: emitted as ISO-8601 string literals.
- JSON: emitted as a quoted JSON string the target's JSON type accepts.
- Everything else: escaped per the target dialect's quoting rules.
See it on your own schema
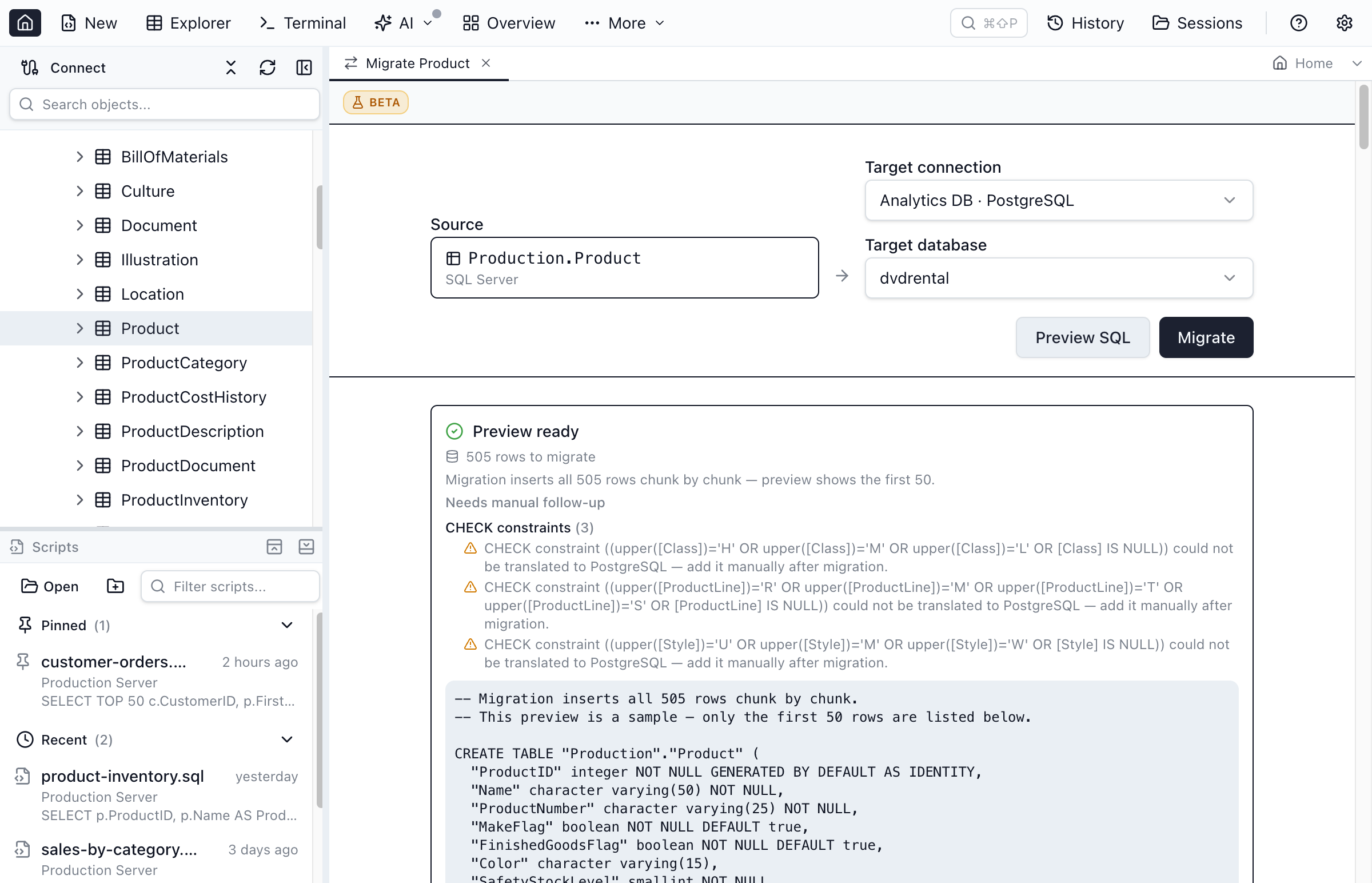
This table is the reference; the migration tool shows you the result on your actual columns. Right-click a SQL Server table, choose Migrate Table to Connection, pick a Postgres target, and the preview renders the translated CREATE TABLE — every column already mapped, every unmapped type flagged. The same canonical model drives cross-engine Schema Compare, so you can diff a SQL Server table against its Postgres counterpart and get a green "identical" verdict for the columns that translated cleanly.
Frequently asked questions
What does SQL Server bit map to in PostgreSQL?
SQL Server bit maps to PostgreSQL boolean. The stored values 0 and 1 are coerced to FALSE and TRUE when rows are copied, because a PostgreSQL boolean literal is TRUE/FALSE, not 0/1. Note that PostgreSQL's own bit and bit varying types are bit strings, not booleans, so they are not a mapping target.
What is the PostgreSQL equivalent of SQL Server uniqueidentifier?
SQL Server uniqueidentifier maps to PostgreSQL uuid. Both are native 16-byte UUID types, so the mapping is lossless in both directions.
How does nvarchar map to PostgreSQL?
nvarchar(n) maps to character varying(n) and nvarchar(max) maps to text. PostgreSQL columns are Unicode by virtue of the database encoding (typically UTF-8), so there is no separate N-prefixed type to map to. The N-prefix byte width is converted to a character count so nvarchar(50) and varchar(50) both become character varying(50).
What does datetime2 map to in PostgreSQL?
datetime2(n) maps to timestamp(n) without time zone, preserving the fractional-seconds precision. SQL Server datetimeoffset(n) maps to timestamp(n) with time zone. Legacy datetime maps to timestamp(3) and smalldatetime to timestamp(0).
Is the SQL Server to PostgreSQL type mapping reversible?
Yes, the mapping is symmetric: it routes every type through a canonical type model, so the same engine maps PostgreSQL back to SQL Server (and between any pair of MSSQL, PostgreSQL, MySQL, Oracle, and SQLite). A few cases are documented as lossy — money loses its spelling, tinyint widens to smallint, and PostgreSQL char types come back as N-prefixed SQL Server types because they are Unicode.
Apply This Mapping in Two Clicks
Right-click a table, pick a target engine, preview the translated DDL. MSSQL, PostgreSQL, MySQL, Oracle, SQLite. Free for personal use.