Last updated: 2026-06-14
Schema Compare
Compare database schemas across SQL Server, PostgreSQL, MySQL, MariaDB, Oracle, and SQLite to identify structural differences. View changes to tables, views, stored procedures, indexes, constraints, and other objects. Generate engine-specific DDL scripts to synchronize schemas between environments.
What is Schema Compare?
Schema compare is a database tooling feature that analyzes two databases and lists every structural difference — tables, columns, indexes, views, stored procedures, functions, triggers, and constraints that differ. The output is typically a side-by-side diff plus a DDL script (ALTER, CREATE, DROP) that can synchronize one database to match the other.
Schema compare tools are used to:
- Verify that a deployment applied all expected migrations
- Promote a schema from development → staging → production
- Audit drift between environments that should match
- Generate rollback scripts before risky schema changes
“JamSQL has been a lifeline for MacBook users. It's replaced several SQL tools in my workflow, and I'm still discovering new features. The support team is genuinely helpful, and clearly invested in their customers' success.”
Schema Compare vs Data Compare
These two Jam SQL Studio tools are often confused. They are complementary, not overlapping:
| Aspect | Schema Compare | Data Compare |
|---|---|---|
| What it compares | Database structure (tables, columns, procedures, etc.) | Table rows (actual data values) |
| Typical use case | Promote DDL from dev → prod | Sync reference data or audit row-level drift |
| Output script | ALTER TABLE, CREATE INDEX, etc. | INSERT, UPDATE, DELETE by primary key |
| Safe on production? | Review carefully — DDL is often irreversible | Usually safer — DML can be wrapped in a transaction |
If you need both, run schema compare first (to align structure), then data compare (to align rows).
Getting Started
Schema Compare helps you understand the differences between two database schemas. Whether you're comparing development to production, or verifying a deployment, this tool shows exactly what has changed.
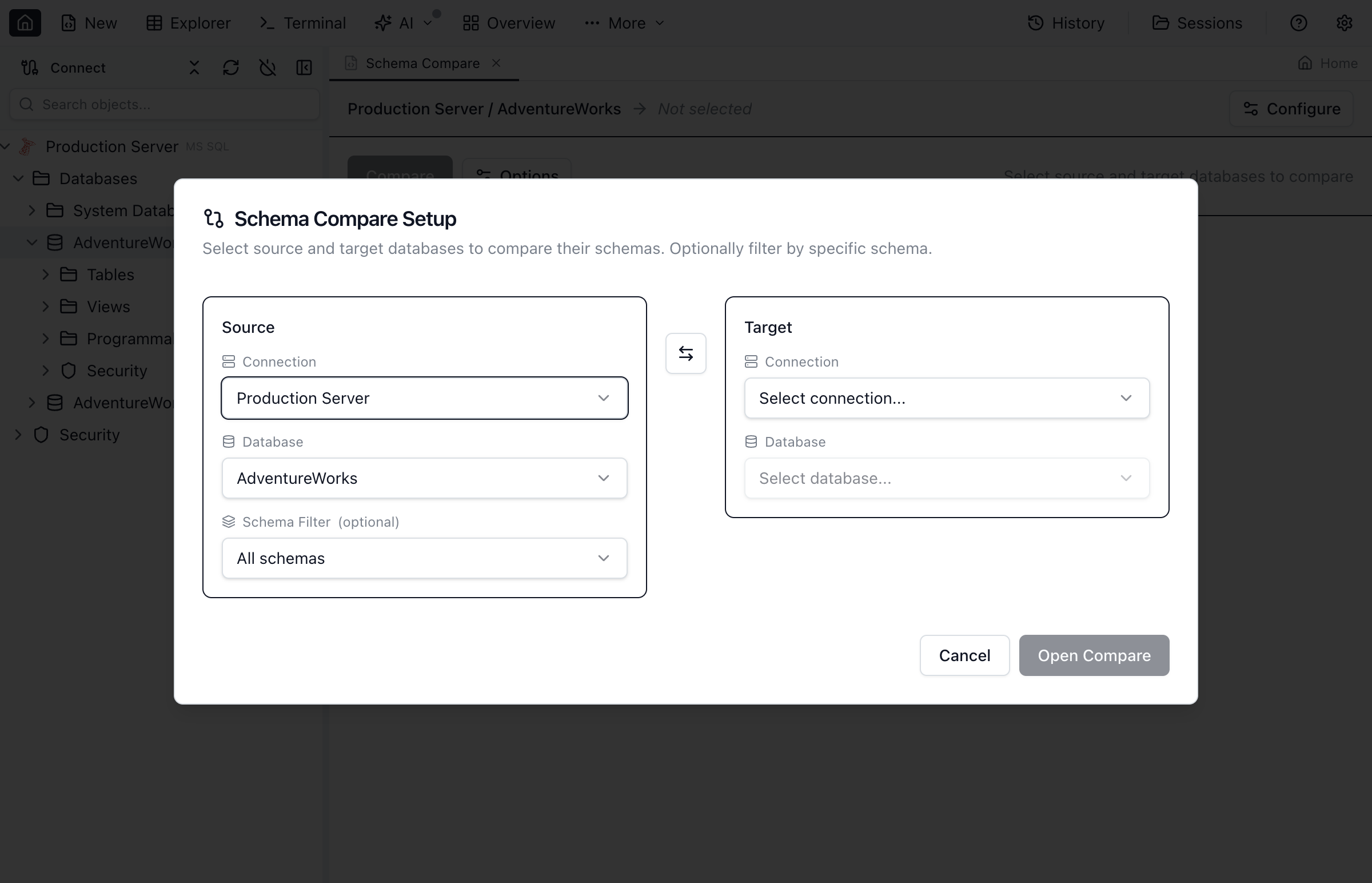
How to Start a Schema Comparison
- Open Jam SQL Studio and connect to both source and target databases
- Click Tools > Schema Compare from the main menu
- Select the source connection and database from the dropdown
- Select the target connection and database
- Click Compare to analyze the differences
Filtering schemas
For databases with many schemas, narrow a comparison to just the ones you care about. Each side of the setup dialog has a Schema Filter chip picker with two modes:
- Include — compare only the listed schemas. Useful when you want to focus a comparison on a single subsystem (for example, just
dbo). - Exclude — compare everything except the listed schemas. Useful for skipping noisy schemas like
auditorstaging.
Add schemas by clicking Add and picking from the dropdown. An empty filter means “all schemas” — the default. The filter is saved with the comparison tab and surfaces in Recently compared entries.
System schemas
System schemas (sys, INFORMATION_SCHEMA, pg_catalog, pg_toast, MySQL's mysql / performance_schema, Oracle's SYS / SYSTEM, etc.) are excluded from comparisons by default. This matters most when comparing a local database against a managed cloud database such as Azure SQL Database or Amazon RDS, where the platform injects management objects (firewall rules, audit metadata) that you can't replicate locally and that would otherwise show up as never-reconcilable diffs.
To include them — for example, when running a DBA-level comparison — tick Include system schemas in the schema-filter section of the Setup dialog.
Compare depth
The Setup dialog exposes a Compare depth selector that picks how much per-table metadata to fetch and which volatile properties to ignore. Pick the preset that matches the comparison you're running:
- Quick — columns only. Skips indexes, foreign keys, triggers, table options, and partition definitions. Use this on very large schemas when you only care about column-level drift.
- Standard (default) — columns, constraints, indexes, foreign keys. Engine-specific volatile-storage properties (e.g. SQL Server
fillfactor, identity seed/increment, data compression; MySQLAUTO_INCREMENT; OraclePCTFREE/PCTUSED/INITRANS) are pre-ignored so they don't drown out real differences. - Deep — everything Standard covers, plus triggers, engine-specific table options, and partition definitions. No properties are pre-ignored.
If you tick or untick individual checkboxes in Advanced below, the depth selector switches to Custom to indicate that the current options no longer match a preset.
Object types and advanced options
Below the depth selector, the Setup dialog lets you include or exclude object types from the comparison — Tables, Views, Stored Procedures, Functions. Engines that don't support a type (SQLite has no procedures or functions) hide the corresponding checkboxes automatically.
The setup dialog also exposes a first-class Format SQL during comparison toggle (on by default). When on, view, procedure, function, and trigger definitions are run through the engine-aware SQL formatter on both sides before classification — so two routines that differ only in indentation or keyword case collapse to Identical instead of crowding the tree as Modified. The DDL diff pane has a per-comparison Formatted / Raw toggle so you can flip back to the unformatted text for one comparison without re-running. When formatting falls back to a basic regex mode (rare — happens for syntax the parser doesn't recognise), a small warning chip appears in the diff toolbar with a one-click link to switch to Raw.
The collapsible Advanced section exposes the remaining knobs:
- Ignore case differences in identifiers — useful when comparing case-sensitive engines against case-insensitive ones, or when you've renamed objects between cases.
- Ignore whitespace in view/routine definitions — suppresses formatting-only differences in stored procedure, function, and view bodies. Greyed out when Format SQL during comparison is on (which already collapses whitespace and keyword-case drift).
- Ignore These Properties When Comparing — a checklist of table-level and column-level properties that can be suppressed from the diff. The list is filtered to your engine, so a PostgreSQL comparison only shows PostgreSQL-relevant properties (
tablespace,UNLOGGED,INHERITSparents, …) and never SQL Server'smemoryOptimizedor SQLite'sWITHOUT ROWID.
Recently Compared
The setup dialog remembers the source and target databases you've compared previously. Pick the most recent comparison from the Recently compared section at the bottom of the dialog to pre-fill source, target, and mode in one click.
- The most recent comparison is shown directly. Earlier comparisons collapse behind a Show N earlier comparisons toggle.
- When the expanded list contains two or more entries, a search box filters them by connection or database name.
- Each entry shows whether the comparison was a whole database or a single object, and how long ago it ran. Hover over an entry to remove it from history.
- Entries whose connection no longer exists are marked connection unavailable — clicking still pre-fills the saved values so you can re-pick the connection.
Personal Mode Limits
Schema Compare is available in both Personal and Pro modes, with different limits:
- Personal mode - Full comparisons are available when both schemas have 200 objects or fewer (tables + views + procedures + functions). Larger schemas require Pro.
- Pro mode - No schema-size limits.
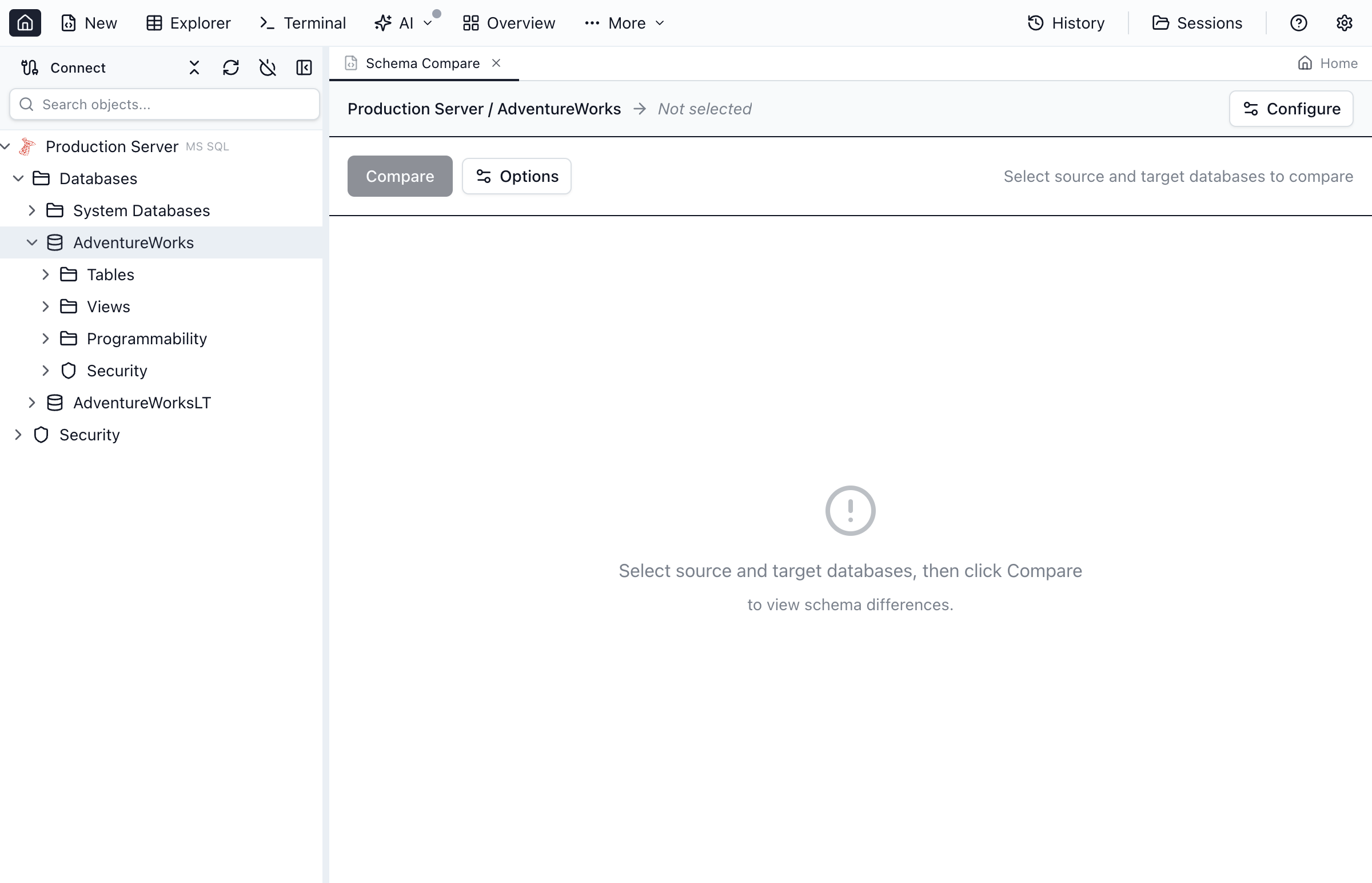
Understanding the Results
After the comparison completes, the object list opens on a top-level Overview entry that's selected by default. Below it, all database objects are organized by type in a tree view. Each object is color-coded to indicate its status:
Overview
The Overview pane is a bird's-eye view of the diff. It shows totals for added, modified, removed, and identical objects across every category, plus an adaptive grid of object cards. For modified tables you see the actual changed columns inline (with type changes called out); for modified views and routines you see line-count deltas. Use the Compact / Cards / Detailed density toggle to dial in the level of detail — when there are many changes the view automatically switches to a dense layout. Click any card to jump straight to that object's DDL diff.
Viewing Object Details
Click on any object in the results to see a side-by-side diff view showing exactly what has changed. The diff highlights additions in green and deletions in red. The Source database is always on the left and the Target on the right, matching the Source → Target direction shown in the workspace header and in the generated sync script. Each pane has its own header with a role badge, the connection alias and database name, and the underlying server — hover for the full connection details.
When a table is marked Modified but the CREATE TABLE statement looks identical, Schema Compare surfaces the actual difference in two ways. A banner above the diff editor lists the dependent objects (indexes, constraints, triggers) that differ, and the differing dependents' CREATE statements are appended inline to the source and target panes so the side-by-side view highlights the delta. Identical dependents are not shown — only the ones that differ are inlined.
Table-Level Coverage Beyond Columns
Schema Compare diffs more than just columns and constraints. Per-engine table options, generated/computed expressions, identity seed and increment, collation, comments, and partition definitions are all captured and surfaced. When two tables differ only on one of these dimensions, the table is correctly flagged as Modified and the affected property appears in the dependents banner.
- SQL Server — data compression, fillfactor, memory-optimized, durability,
MS_Descriptionextended properties (table + column), partition function/scheme, identity seed/increment, computed columns. - PostgreSQL — tablespace, fillfactor,
UNLOGGED,INHERITSparents,COMMENT ONon tables and columns, partition definition (RANGE/LIST/HASH), stored generated columns, per-column collation. - MySQL — storage engine, row format, default charset and collation,
AUTO_INCREMENT, table and column comments, generated columns, partition method and expression. - Oracle — tablespace,
PCTFREE/PCTUSED/INITRANS, compression, logging, organization (HEAPvsINDEX), table and column comments, identity seed and increment, virtual columns, partition strategy and sub-strategy. - SQLite —
WITHOUT ROWID,STRICT, generated columns parsed from the originalCREATE TABLEtext.
Drill-Down Diff Details
When a table has many differences spread across multiple dimensions, the dependents banner caps inline display at twelve entries and shows a View all N differences → link. Clicking it opens a drill-down dialog that lists every difference grouped by kind (columns, constraints, indexes, triggers, options, partition) with the source and target values shown side-by-side for option-level changes. Press Escape or click outside to close.
Ignoring Volatile Properties
Some properties — fillfactor, auto-increment, identity seed and increment, Oracle PCTFREE / INITRANS — change frequently in production and rarely indicate a meaningful schema difference. The Standard depth preset pre-ignores the engine-specific volatile-storage subset for you; the Advanced section of the Setup dialog exposes the full engine-filtered list under Ignore These Properties When Comparing so you can fine-tune which properties contribute to the diff.
Generating Synchronization Scripts
Once you've reviewed the differences, you can generate a DDL script to synchronize the target database with the source schema.
Script direction
The results toolbar exposes a Generate script for: segmented control with two options — Source → Target (default) and Target → Source. Flipping the toggle changes which database the generated script will modify, without re-running the comparison. The visual diff always stays Source on the left, Target on the right; only the script's destination changes. The script preview dialog shows a banner near the top stating "This script will modify <destination alias / db> to match <origin alias / db>", and the Open in Query Tab action attaches the script to whichever connection is currently the destination.
Steps to Generate a Script
- Review the comparison results and uncheck any objects you don't want to include
- (Optional) Use the Generate script for: toggle to flip the direction
- Click Generate Script to preview the synchronization script
- Review the generated DDL statements in the preview pane (the destination banner restates what the script will modify)
- Click Open in Query Tab to load the script against the destination connection (safer default — one click never executes), or open the dropdown next to it and pick Open & Execute to load the script and immediately kick off the normal execute flow. Because sync scripts contain DROP statements, the standard destructive-query confirmation dialog gates the actual execution.
Key Capabilities
- Full schema support - Compare tables, views, stored procedures, functions, triggers, indexes, and constraints
- Visual diff - Side-by-side view with syntax highlighting shows exactly what changed
- Selective sync - Choose specific objects to include or exclude from the synchronization
- Safe script generation - Preview the DDL before executing with transaction wrapping
- Cross-connection support - Compare schemas across different SQL Server instances
Schema Compare for SQL Server, PostgreSQL, MySQL, and Oracle
The Schema Compare workspace is engine-aware: it picks up the source and target connection's grammar, generates DDL in the right dialect, and matches objects by their natural identity (schema-qualified names, signatures for overloads). Same-engine compare covers every object type listed below; comparing two databases on different engines compares tables in full plus a name-presence inventory of views, procedures, functions, and triggers (see Cross-engine compare & migration). Below is what each engine adds beyond the common feature set.
| Engine | Object types compared | Engine-specific behavior |
|---|---|---|
| SQL Server | Tables, views, stored procedures, scalar / inline / multi-statement TVFs, triggers, indexes, foreign keys, check constraints, schemas, user-defined types, sequences | Generates ALTER TABLE with WITH NOCHECK options where safe; preserves SCHEMABINDING; respects clustered index drop-and-recreate ordering. Works with on-prem SQL Server 2017+ and Azure SQL Database. |
| PostgreSQL | Tables (incl. partitioned), views, materialized views, functions (incl. overloads), procedures, triggers, indexes, foreign keys, check constraints, schemas, custom types, enums, sequences | Honors function-overload signatures so two functions with the same name but different argument types are diffed independently. Generates CREATE OR REPLACE where the engine supports it. |
| MySQL / MariaDB | Tables, views, stored procedures, functions, triggers, indexes, foreign keys, events | Detects engine + collation drift (InnoDB vs MyISAM, utf8mb4 vs utf8mb3) at the table level — common cause of replication issues that plain DDL diffs miss. |
| Oracle | Tables, views, materialized views, packages (spec + body), procedures, functions, triggers, indexes, sequences, synonyms, types, constraints | Treats package spec and body as a pair so a body-only change doesn't invalidate the spec. Generates ALTER PACKAGE…COMPILE after dependent changes. |
| SQLite | Tables, views, indexes, triggers | Because SQLite's ALTER TABLE is limited, generated scripts use the documented "12-step" rebuild pattern (rename, create, copy, drop, rename back) for column changes that other engines do in-place. |
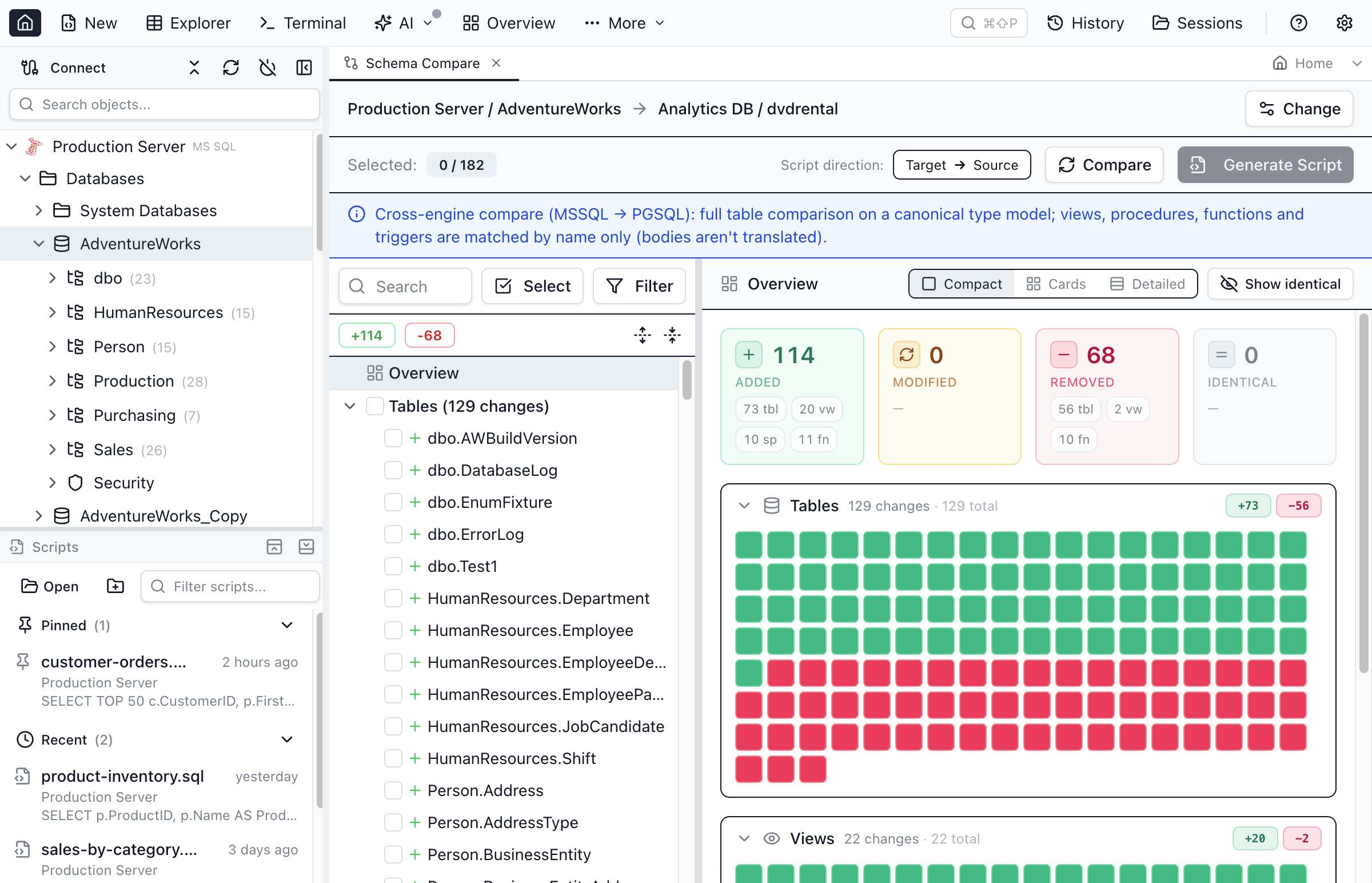
Cross-engine compare & migration
Source and target connections can be on different engines — for example SQL Server vs PostgreSQL. Tables are compared in full (and can be migrated across engines). Views, procedures, functions, and triggers are compared by name presence only — so you get a clear inventory of what exists on one side but not the other, which is exactly the list you need to hand-port. Their bodies are never auto-translated or migrated, because T-SQL and PL/pgSQL don't map 1:1.
- Matching across engines. A table (or view / routine / trigger) in one engine's default schema is matched to the same-named object in the other engine's default schema, so SQL Server
dbo.Customerslines up with PostgreSQLpublic.Customersinstead of showing up as a phantom add/remove pair. - Canonical type comparison. Column types are compared on a shared canonical model, so
nvarchar(100)(SQL Server) andcharacter varying(100)(PostgreSQL) are recognised as the same column rather than a difference. - Object inventory, not body diff. A view or stored procedure that exists on both sides reads as present (no false "modified" from dialect differences); one that exists on only one side reads as added or removed. If you generate a sync script across engines, those objects come through as
-- [MANUAL PORT]notes rather than an invalid foreign-dialect body.
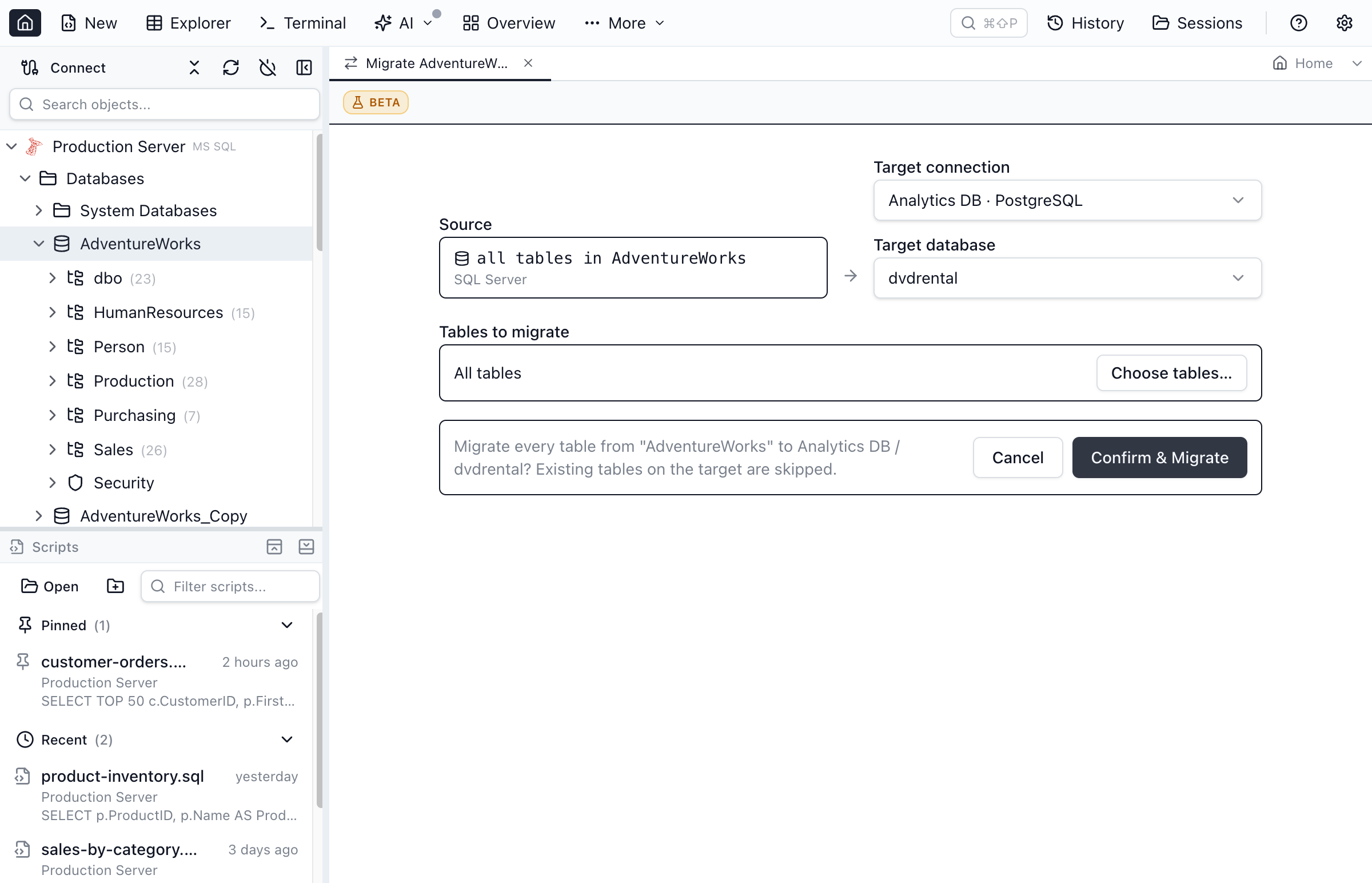
Migrate a table to another connection
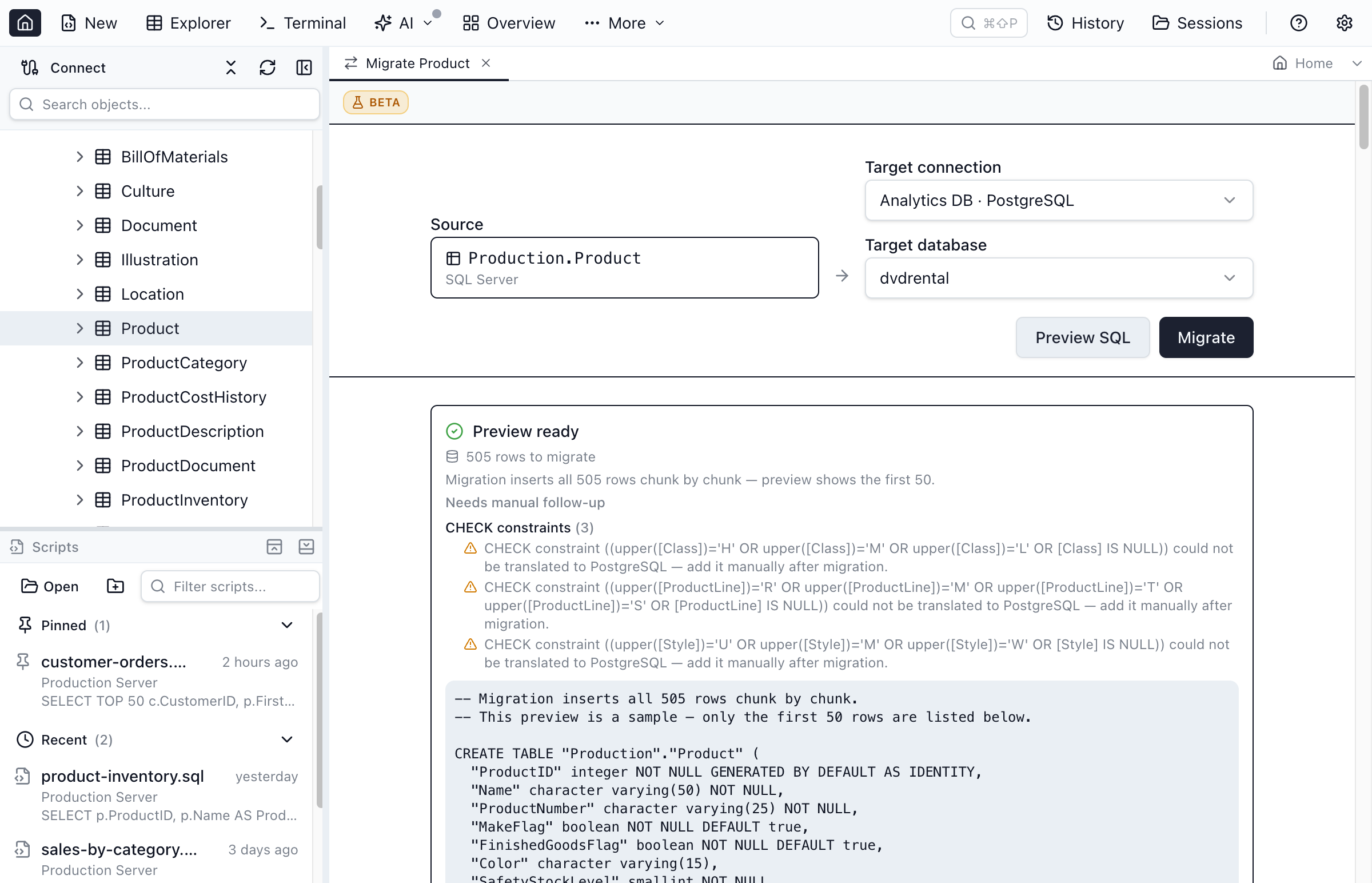
Right-click a table in the Object Explorer and choose Migrate Table to Connection… to copy it — schema and data — into a connection of any engine. To copy an entire database, right-click the database and choose Migrate all tables to connection…. Because a migration can be long-running, it opens in its own workspace tab rather than a modal dialog.
- Pick the target connection and database. Each table is created in the target's default schema in the target dialect.
- Type and value translation runs automatically — e.g. a SQL Server
bitcolumn lands as a PostgreSQLboolean, and numeric/text values are coerced to fit the target column. - Preview (single table) performs a dry run that shows the generated
CREATE TABLE+INSERTscript, the exact number of rows it will copy, and any translation warnings without touching the target — reporting its progress live (analyzing → counting rows → building script) as it works. The script lists at most a 50-row sample ofINSERTs with a banner noting the full table is streamed chunk by chunk, so previewing a multi-million-row table stays instant. - Migrate asks for an explicit confirmation, then streams the copy live in the tab — the current table and phase (creating schema → copying data), an overall progress bar, and rows-copied of the total. Data is read and inserted in chunks, so a large table never loads entirely into memory. Row counts are verified on both sides afterward.
- Cancel stops the run at the next chunk boundary; if a table was only partially copied, you're asked whether to drop the partial table(s) or keep what was copied so far.
- When migrating a whole database, Choose tables… opens a two-list picker (Available ↔ Selected) with search on both sides — migrate every table, or search and bulk add/remove just the subset you want.
- If a target table already exists, the migration is refused with a clear message rather than a raw engine error — drop it or pick a different target and retry. When migrating a whole database, existing tables are skipped (and reported) while the rest continue.
Common Schema Compare Workflows
Three concrete workflows account for most of how teams use schema compare day-to-day. Each one is a few clicks in Jam SQL Studio.
1. Promote dev → staging → production
You've added a new orders.shipped_at column and an index in development. To roll it forward:
- Set source = dev connection / database, target = staging connection / database, click Compare.
- Open the Overview pane — you'll see "1 column added on
orders", "1 index added". - Uncheck anything in the diff that's not part of this change (drift you don't want to ship now).
- Click Generate Script. The output is something like:
ALTER TABLE [dbo].[orders] ADD [shipped_at] DATETIME2 NULL; GO CREATE INDEX [IX_orders_shipped_at] ON [dbo].[orders] ([shipped_at]); GO - Save the script as
2026-05-06-orders-shipped-at.sql, commit it to your migrations folder, and apply with Apply to Target after backup. - Repeat staging → production with the same script — the diff confirms staging now matches production-minus-this-change before you ship.
2. Audit drift between environments that should match
Two environments that "should" be identical often aren't. Run a compare with the source and target swapped, or just look at Modified + Removed on a single direction.
- Index drift — a hot-fix index added in production but never back-ported to dev shows up as "Removed" when source is dev.
- Permission and role drift — not in the schema compare scope; use Security Manager for that.
- Collation / engine drift — common in MySQL where one replica was rebuilt with a different default. Schema Compare flags it at the table-options level.
3. Verify a deployment landed cleanly
After running a migration on production, point Schema Compare at production as source and the migration's expected end-state (a checkout of staging or a freshly-built canary) as target. The expected outcome is "0 differences". Anything else is a deployment problem — missed migration, partial run, or a permission failure.
4. Generate a rollback script before a risky change
Before a schema change, capture the current state by comparing target vs target with no source — or simply compare the new state (post-deploy) back to the old state. The generated DDL is your rollback. Save it alongside the forward migration. This is the safest pattern when you can't easily restore from backup.
Schema Compare Tool Limitations & Edge Cases
Knowing where Schema Compare doesn't help saves time. These are the real boundaries:
- Cross-engine compares don't translate object bodies. SQL Server vs PostgreSQL, Oracle vs MySQL, etc. compare tables in full (canonical type model, migratable across engines) and report views, procedures, functions, and triggers by name presence so you can see what's missing on each side. The bodies of those objects are never auto-translated — T-SQL and PL/pgSQL don't map 1:1 — so port them by hand, using the Object Explorer's Script as CREATE output as a starting point. Sequences are not compared across engines.
- Data is not compared. Schema Compare only looks at structure. Use Data Compare for row-level diffs, especially for reference / lookup tables.
- Permissions, roles, and logins are out of scope. Use Security Manager for those.
- Computed-column expressions are compared as text. Two semantically equivalent expressions that differ in whitespace or parenthesization will show as Modified. Most tools have this limitation; reformat both sides if needed.
- Personal mode caps at 200 objects per side. A 200-table schema with 50 views, 100 procedures, and 50 functions = 400 total — over the limit. Pro mode removes the cap.
- SQL Server temporal-table history is treated as a regular table. History tables show up as separate objects in the diff — safe, but can be noisy. Use the object-type filter to hide them when reviewing.
Best Practices
- Always backup your target database before applying schema changes
- Review carefully - Check the generated script for potentially destructive changes
- Test in staging before applying changes to production
- Use source control - Save generated scripts for audit trails
Frequently asked questions
How do I compare database schemas in Jam SQL Studio?
Open Tools > Schema Compare, select your source and target connections, choose the databases to compare, and click Compare. The tool analyzes both schemas and shows a tree view of all differences organized by object type.
Can I compare schemas across different SQL Server instances?
Yes, Jam SQL Studio's schema compare supports cross-connection comparisons. You can compare a development database on your local machine against a staging or production database on a different server.
What database objects does schema compare support?
Schema compare supports tables, views, stored procedures, functions, triggers, indexes, constraints, schemas, and user-defined types. You can filter which object types to include in the comparison.
How do I generate a synchronization script?
After comparing, review the differences and uncheck any objects you want to exclude. Click Generate Script to create ALTER/CREATE/DROP statements wrapped in a transaction. Preview the script before executing or saving it.
Is it safe to apply schema changes directly?
Jam SQL Studio generates scripts with transaction wrapping and includes safety comments. Always backup your target database before applying changes, review the generated DDL carefully, and test in a staging environment first.
Which database engines does Jam SQL Studio's schema compare support?
Schema Compare works across SQL Server, PostgreSQL, MySQL/MariaDB, Oracle, and SQLite. Same-engine compare covers all object types (tables, views, procedures, functions, sequences). Cross-engine compare (e.g. SQL Server vs PostgreSQL) is supported for tables, and a companion 'Migrate Table to Connection…' action copies a table's schema and data to a connection of any engine with type and value translation.
Is there a free schema compare tool for SQL Server?
Yes. Jam SQL Studio's Personal mode includes Schema Compare for free when both schemas have 200 objects or fewer (tables + views + procedures + functions). Larger schemas need Pro. Microsoft retired Azure Data Studio's SQL Database Projects extension in February 2026, so Jam SQL Studio is a current free option for SQL Server schema diffs.
Ready to Compare Schemas?
Download Jam SQL Studio and start comparing your database schemas today.