Last updated: 2026-07-02
Database Blueprint
Materialize your SQL Server, PostgreSQL, MySQL, Oracle, or SQLite database as a folder of .sql files, kept in two-way sync with one or more linked databases. Track the folder in Git, share it with your team, and apply local edits to tables, views, procedures, functions, and schema definitions back to the database with the built-in Schema Compare hand-off. It's not just schema either — capture table data into the same folder and push row changes back with Sync data folder → DB.
- DB → folder works for every object kind (tables, views, procedures, functions, triggers, schemas, …). Refresh from DB rewrites the corresponding
.sqlfile every time. - Folder → DB via Apply schema to DB picks up your local edits to tables, views, procedures, functions, and schema definitions. Editing
Tables/*.sql(adding or dropping a column, changing a type, toggling nullability, changing a default, adding a CHECK / UNIQUE / FK, changing the primary key, adding a computed column) round-trips back across SQL Server, PostgreSQL, MySQL, and Oracle. SQLite supports add / drop column only — the engine has no in-placeALTERfor other changes, so those still need a full table rebuild via the usual SQL workflow. - Row data round-trips via Table data + Sync data folder → DB (see below).
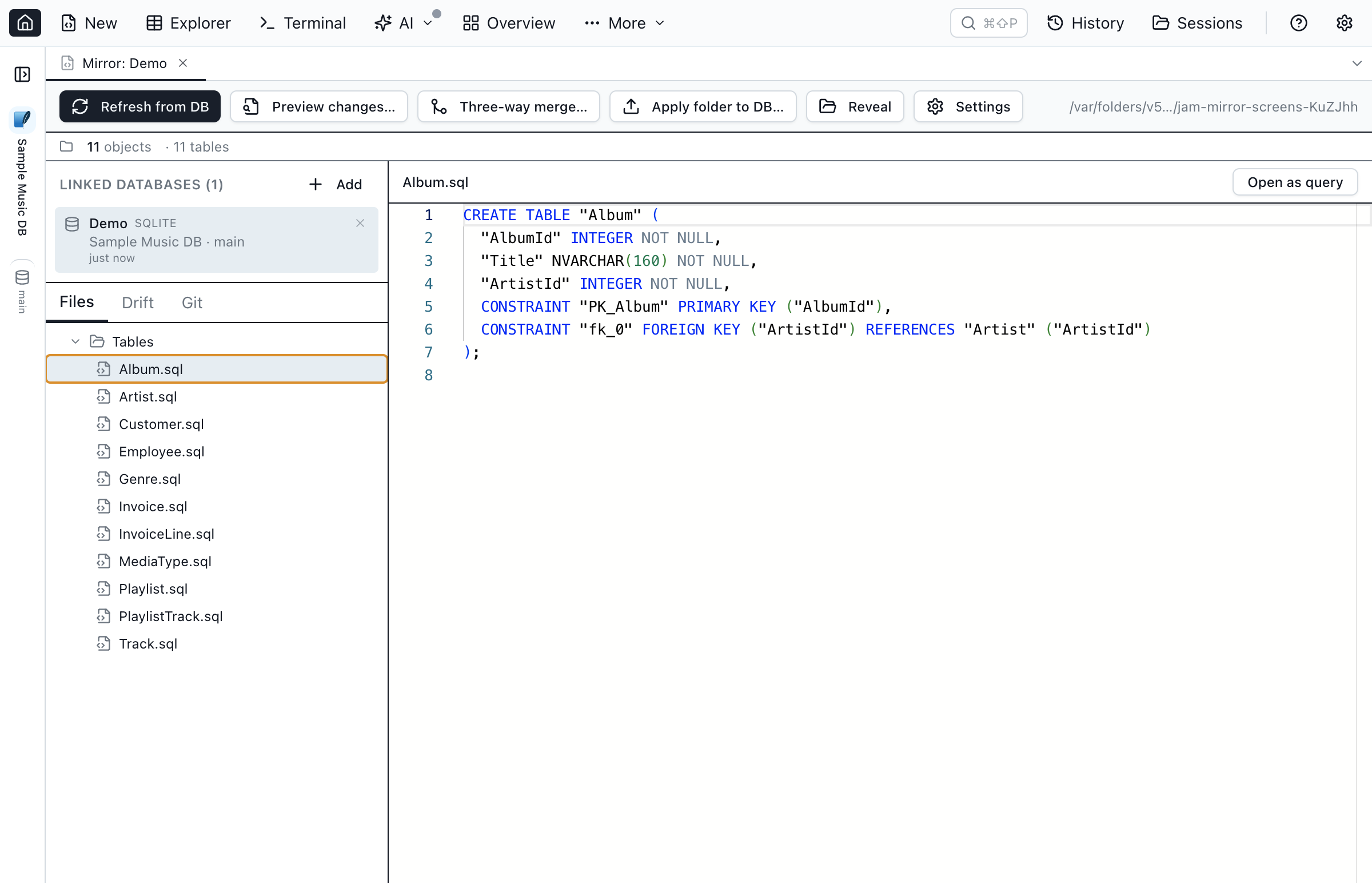
.sql file kept in sync with the linked database.What is Database Blueprint?
A Database Blueprint is a directory on disk that blueprints a database's complete DDL — one .sql file per table, view, stored procedure, function, and schema. The folder can be linked to one or more databases and kept in sync through three actions:
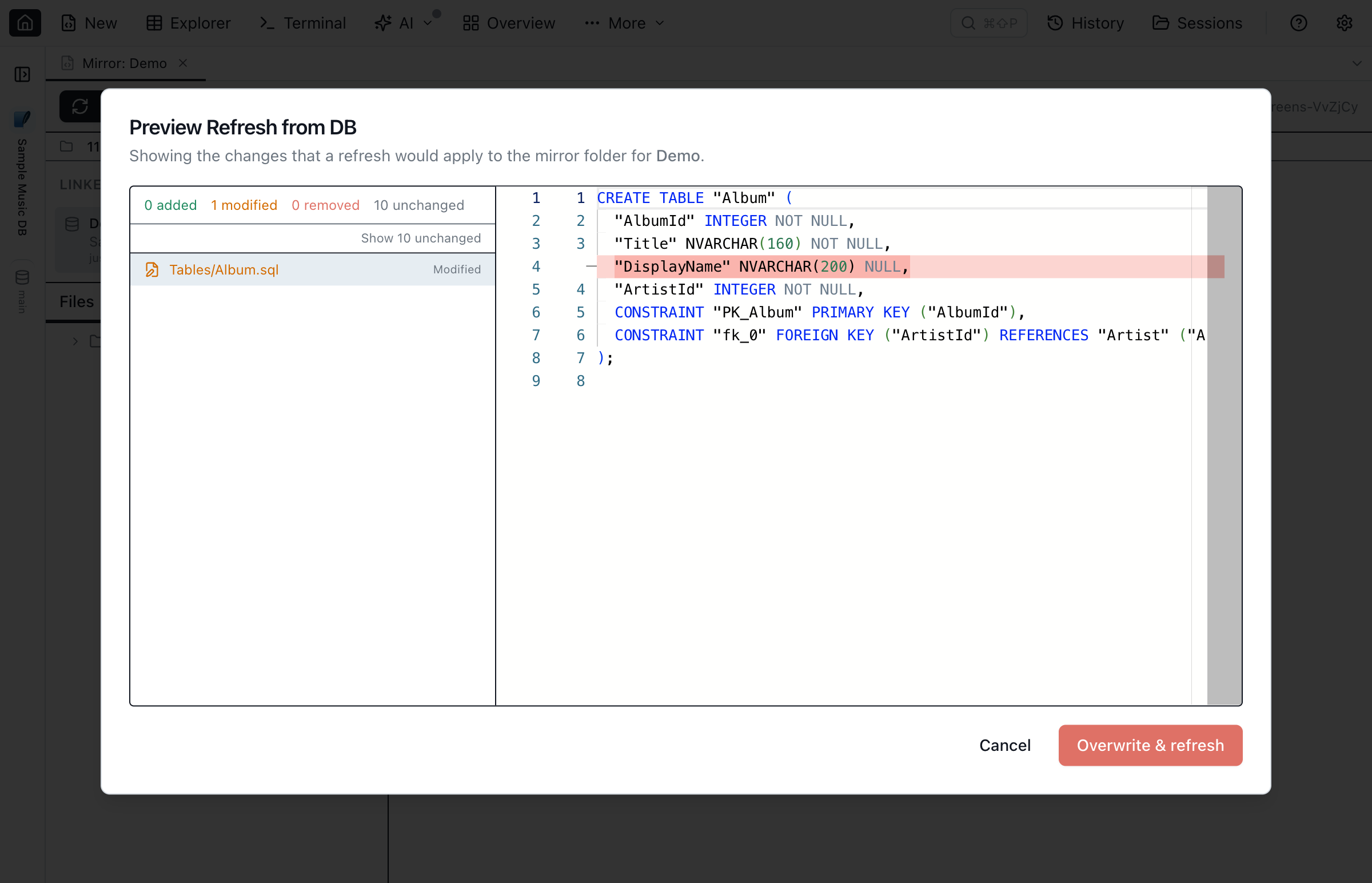
- Refresh from DB — re-emit every object's DDL from the linked database, overwriting local files. The dialog previews the pending changes first (added / modified / unchanged / removed, with a Monaco diff per file) and only writes once you click Confirm refresh.
- Three-way merge — compare local edits, baseline (last refresh), and the live database to identify clean merges and true conflicts, including table DDL edits in
Tables/*.sql. - Apply schema to DB — reuse Schema Compare with the folder as the source endpoint and the linked database as the target, generating a synchronization script for tables, views, procedures, functions, and schema definitions. (SQLite table edits cover add / drop column only.)
Creating a Database Blueprint
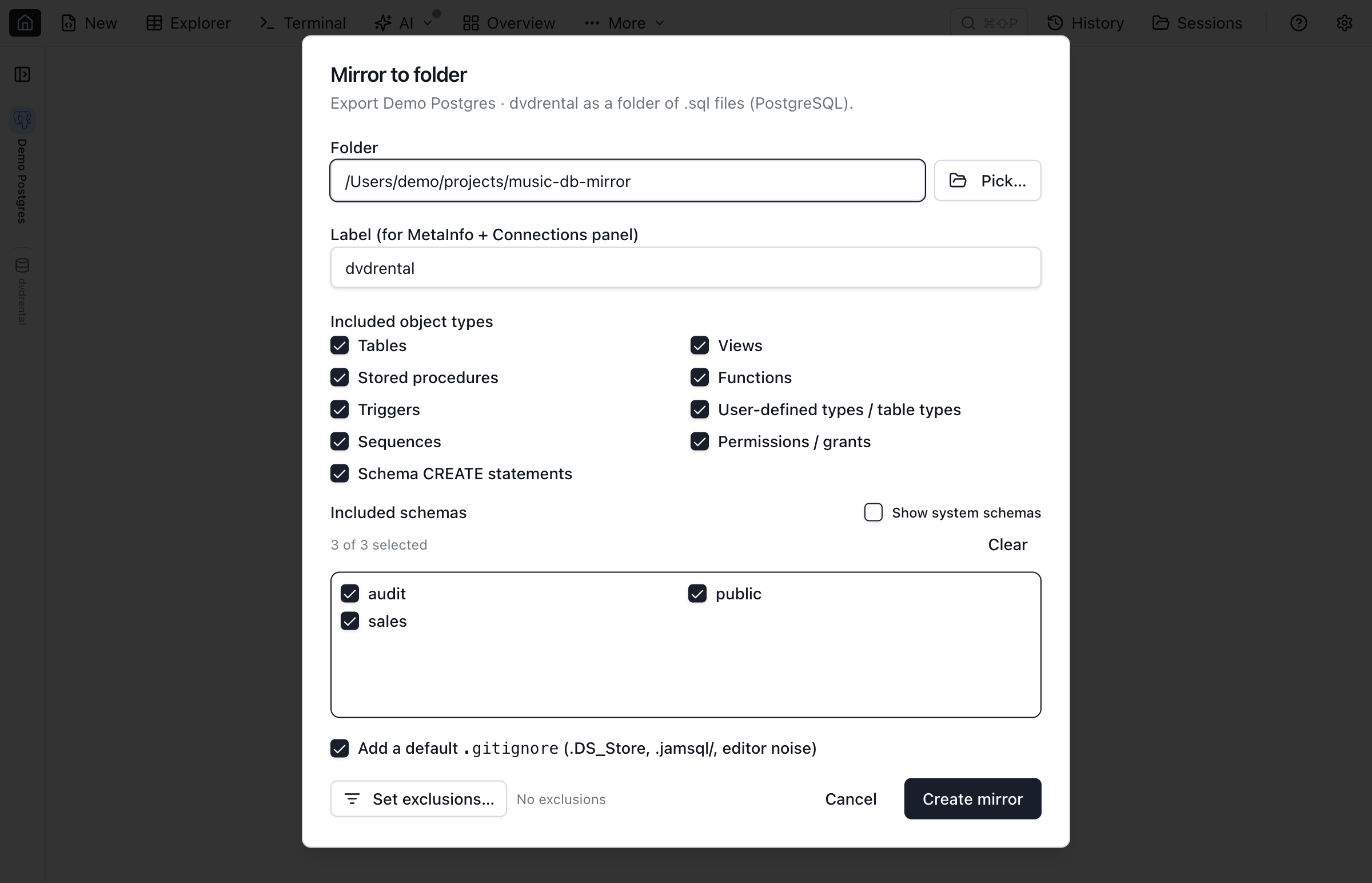
- Pick a database in the Object Explorer (or open the command palette with Cmd/Ctrl+Shift+P and search for "Database Blueprint").
- Choose an empty folder, give the link a label (e.g.
Dev,Stage,Prod), and select which object types and schemas to include. - Optionally write a default
.gitignorecovering.DS_Store,.jamsql/snapshots/(per-user baseline cache, not shared), and editor noise. TheData/folder is not gitignored — teammates need those sidecar files for Sync Data. - Click Create Database Blueprint. Jam emits the DDL, writes a
jamsql-blueprint.jsonmanifest, writes a per-linkjamsql-meta-<label>.jsonMetaInfo file, and opens the Database Blueprint tab.
Attaching an existing blueprint folder
If a colleague shares a blueprint folder with you via Git or a shared drive, you don't need to recreate it from the database. Open the Create Database Blueprint dialog and click the Attach existing blueprint… link in the footer. A folder picker opens — select the root folder (the one that contains jamsql-blueprint.json). Jam reads the manifest, validates it, and registers the folder in your local blueprint list. You can then open the blueprint tab, switch the active link to your own database connection, and start syncing immediately.
Jam also detects an existing blueprint automatically when you mount a folder that already contains a jamsql-blueprint.json: the Create dialog will ask “This folder already contains a blueprint. Attach it instead of creating a new one?” — accepting registers the folder without overwriting anything on disk.
.sql files in one click.Folder layout
my-blueprint/
├── jamsql-blueprint.json ← manifest (linked DBs, included object types, schemas)
├── jamsql-meta-Dev.json ← per-link MetaInfo (loose FKs, JSON, enums)
├── README.md
├── .gitignore
├── Schemas/
│ └── dbo.sql
├── Tables/
│ ├── dbo.Users.sql
│ └── dbo.Orders.sql
├── Views/
│ └── dbo.OrderSummary.sql
├── Programmability/
│ ├── Stored Procedures/
│ │ └── dbo.usp_UpdateOrder.sql
│ └── Functions/
│ └── dbo.fn_OrderTotal.sql
├── Data/ ← table data artefacts (tracked — shared with teammates)
│ ├── dbo.Users.data.sql ← upsert / replay SQL for the table data
│ └── dbo.Users.data.json ← row sidecar (PK, column types, captured rows)
└── .jamsql/
└── snapshots/ ← per-user baseline cache (not shared, gitignored)
Previewing changes before they land
There's no separate preview action — Refresh from DB always previews first. Click Refresh from DB in the toolbar and the dialog reads the current schema from the database and stops on a preview step before writing anything: a side panel lists every file grouped into Schema and Data sections as added, modified, unchanged, or removed, and a Monaco side-by-side diff renders for the selected file. Nothing on disk changes until you click Confirm refresh; Cancel backs out with your local files untouched.
Excluding individual objects
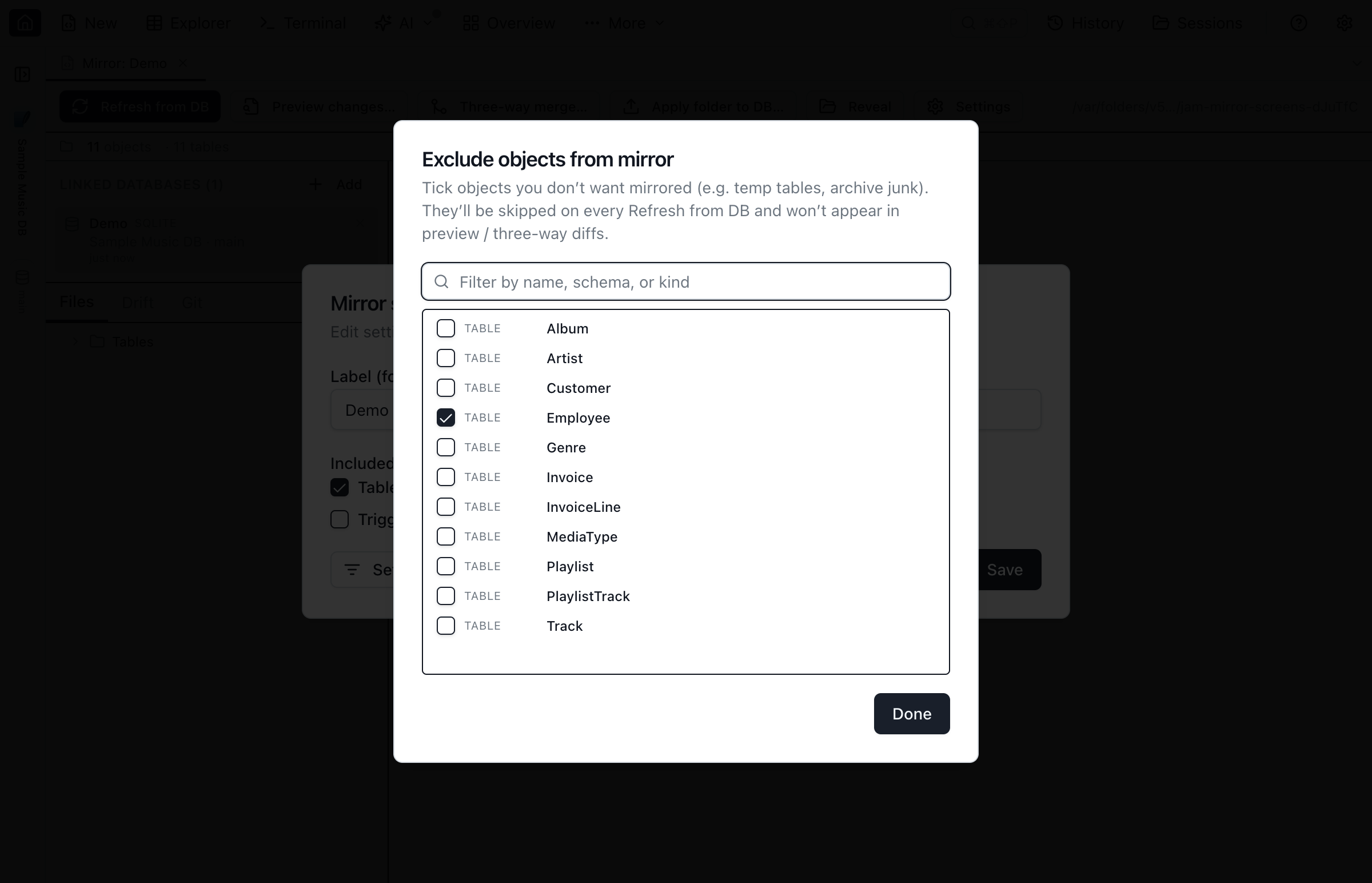
Some database objects don’t belong in a long-lived database blueprint — one-off temporary tables (e.g. tmp_users_20260520), archive junk (zz_old_archive), DBA scratch views, or anything you don’t want to version with the rest of the schema. Both the Create Database Blueprint dialog and the toolbar Settings dialog have a Set exclusions… button in the footer that opens an exclusion picker:
- Open the dialog — either Create Database Blueprint for a brand-new blueprint, or the toolbar Settings button (gear icon) to edit an existing one.
- Click Set exclusions… in the footer (bottom-left). A sub-dialog lists every candidate object, with a filter input to narrow by name, schema, or kind.
- Tick the rows you want to opt out of and click Done. The footer summary updates to show what’s currently excluded.
- Click Create Database Blueprint / Save on the parent dialog to commit the exclusions to
jamsql-blueprint.json.
From then on, excluded objects are:
- skipped by Refresh from DB — no
.sqlfile is written or updated for them, - dropped from the Refresh from DB preview diff — they no longer surface as added or removed,
- dropped from the three-way merge — no merge action is ever proposed for them,
- skipped by Apply schema to DB — which reads the
.sqlfiles directly, so Schema Compare doesn’t propose creating or dropping them on the target.
Files already on disk are left alone when you add an exclusion — delete them yourself if you want them gone. To re-include an object, un-tick it in the same picker; the next refresh re-emits it. Exclusions live in jamsql-blueprint.json so they version with the rest of the blueprint and sync via git to your teammates.
Editing a blueprint's settings
The toolbar Settings button opens the Database Blueprint settings dialog — the same UI as Create Database Blueprint but pre-populated with the existing label, linked databases, included object types, and excluded objects. Use the Linked databases row to add or remove Dev / Stage / Prod links without re-creating the blueprint. Edit any of the fields, hit Save, then run Refresh from DB to roll the new settings into the on-disk .sql files. Settings changes don’t touch files on disk until you refresh.
Multi-connection links
A single blueprint folder can be linked to several databases of the same engine — typically Dev, Stage, and Prod copies of the same schema. Each link gets its own label, its own baseline cache, and its own MetaInfo file. The toolbar shows the active link as a chip on the left; click it to switch which link Refresh from DB, three-way merge, Apply schema to DB, and Sync data folder → DB target. The same popover lets you add a new link or remove an existing one. Add and remove links also from the Settings dialog if you'd rather edit them alongside the other per-blueprint knobs.
Cloning a teammate's blueprint
A teammate’s Database Blueprint folder is just a regular git repository — git clone it (or open it via Open Database Blueprint folder…) and Jam picks up the jamsql-blueprint.json manifest, the per-link baseline caches, and the jamsql-meta-<label>.json MetaInfo sidecars on first open. The MetaInfo sidecars are merged into your local store automatically with local-wins semantics — your own loose foreign keys, JSON column declarations, and enum declarations on the same (connection, database) are preserved on conflict — so loose FK / JSON / enum chips show up in the Table Explorer and Query Editor without any manual import step. Subsequent git pulls pick up teammate updates the next time the blueprint tab opens.
Sync data folder → DB
When you turn on Table data for a table during Refresh from DB, Jam captures its current rows into a dedicated Data/ folder: a .data.sql upsert script and a .data.json sidecar that preserves the primary key and column types for round-tripping. Schema Compare ignores those files — it only diffs DDL. To push row changes from the blueprint folder back to a linked database, use Sync data folder → DB from the toolbar.
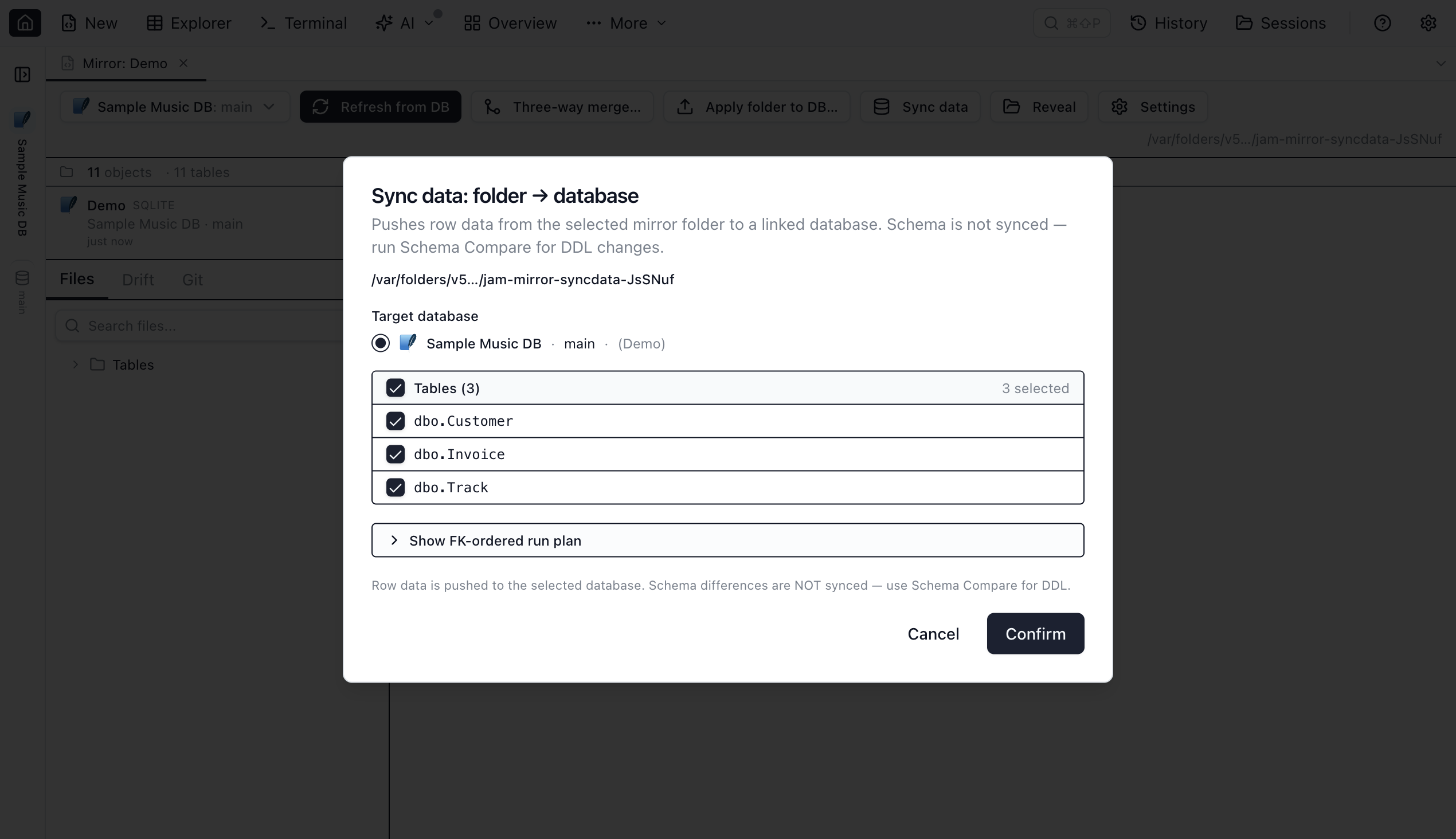
.data.sql tables to push to the linked database, with a collapsible FK-ordered run plan and an explicit schema-not-synced footnote.- Click the Sync data button in the Database Blueprint toolbar. The button is enabled once the blueprint has at least one linked database.
- The Sync data dialog lists every table that has a table data captured. Pick which tables to sync (all selected by default) and confirm the target link. Hit Confirm to begin.
- The progress dialog runs the workflow in two phases. Compare walks the selected tables sequentially, diffing the blueprint folder's rows against the live table on the linked database and surfacing per-table insert / update / delete counts. After all tables compare, the dialog stops at a review step so you can scan the totals before anything is written.
- Hit Apply to push the row changes. The apply phase also runs table-by-table; an error on one table is captured and reported but doesn't abort the rest of the queue.
- Clicking Cancel mid-run stops the queue at the next table boundary — the in-flight table completes first so partial writes don't get stranded.
What it syncs. Row-level inserts, updates, and deletes — driven by the diff between the blueprint folder's data sidecar and the live table. The primary key used for matching rows comes from the sidecar's pk field, so it stays correct even if the live table's PK metadata changes.
Open in Data Compare. Each table row in the Sync Data dialog — and each table on the progress dialog's review ("ready to apply") step — also has an Open in Data Compare action. Instead of the inline quick-sync, it opens the full Data Compare workspace for that single table — the blueprint folder as the source, the active linked database as the target — and auto-runs the comparison. Use it when you want to inspect row-level diffs in the grid, tweak the key / value column mappings or comparison options, and selectively generate a sync script rather than pushing every diff at once. The target side must be a live linked database; tables without a primary key can't be opened this way (Data Compare needs a key to match rows) — use quick sync for those.
What it doesn't sync. Schema (DDL) differences. Those are still handled via Apply schema to DB → Schema Compare. When the Schema Compare setup sees a blueprint folder that contains any .data.sql files, it shows a small banner reminding you that those files are out of scope and points you back to Sync data folder → DB.
Tables without a primary key. Tables emitted with destructive replay (no primary key, sidecar written with an empty pk) appear in the Sync data list but error out during compare with “Sidecar has no primary key — cannot match rows.” Row-level diffing needs a key to match rows across the two sides. If you need to push those tables, re-run the .data.sql upsert script against the target database directly.
Rebuilding data sidecars offline
Sync data folder → DB reads the Data/<schema>.<table>.data.json sidecar — if it's missing (a pre-F1 blueprint that gitignored .jamsql/, a git clean, or a manual delete), Sync Data can't run for that table. When Jam detects missing sidecars it shows a banner at the top of the Database Blueprint tab with two ways to recover: Refresh from DB (re-captures from the live database) or Rebuild from .data.sql — an offline alternative that reconstructs sidecars straight from their sibling .data.sql upsert scripts, no live database connection required.
- Click Rebuild from .data.sql in the banner.
- Confirm the dialog: “Rebuilding treats the current .data.sql files as the new baseline. Continue?”
- Jam decodes every
.data.sqlfile in the folder'sData/directory back into rows and re-writes its.data.jsonsidecar. The banner then reports how many sidecars were rebuilt, and skips (with a reason) any file it can't safely decode — for example one whose upsert statements target a different table than its filename implies.
Fidelity notes. Reconstructing purely from SQL text has a few known blind spots, and the rebuild always calls them out rather than guessing silently:
- Computed/generated columns are absent from
.data.sqlby design (the capture step never emits them) — the rebuilt sidecar marks them absent instead of inventing a value. - Temporal values come back as plain strings rather than a tagged date, since SQL text alone can't always distinguish a date/time literal from an ordinary string.
- Booleans come back as
0/1rather than a tagged boolean, for the same reason. - Empty PostgreSQL arrays come back as the literal string
'{}', ambiguous with an actual empty-string value.
Any of these that apply to the rebuilt tables show up as an expandable fidelity notes list under the banner's result summary. They describe the rebuild's own representation, not a data-loss bug — Sync Data still works correctly against the rebuilt sidecar afterwards.
Viewing captured data
When a table has been added to the table data, its captured rows live in the Data/ folder: Data/<schema>.<table>.data.sql for the upsert script and Data/<schema>.<table>.data.json for the row payload. Click either file in the blueprint tree to open the tabbed viewer:
- Data tab — the captured rows in a read-only grid, with column names, types, and a PK indicator. The footer shows row count and the time the rows were captured.
- Script tab — the upsert SQL in a read-only Monaco editor.
The toolbar’s ← Go to schema button jumps to the corresponding DDL file under Tables/. From the schema view, a Go to data → button appears in the toolbar when the selected table has captured data, jumping back to the Data/ files. The Open as query button always opens the .data.sql in a Query Editor tab if you want to run or edit it.
Editing captured data in Table Explorer
The data viewer’s Edit button opens the table’s captured rows in the full Table Explorer — with column-aware type pickers, filters, sorting, and JSON / enum / loose-foreign-key overlays driven by the table’s MetaInfo — in an in-memory Blueprint edit mode marked by a blue banner. Edits never touch any database: saving writes back to the .data.json sidecar and regenerates the .data.sql upsert script. Use Sync data folder → DB afterwards if you want to push those row changes to a linked database.
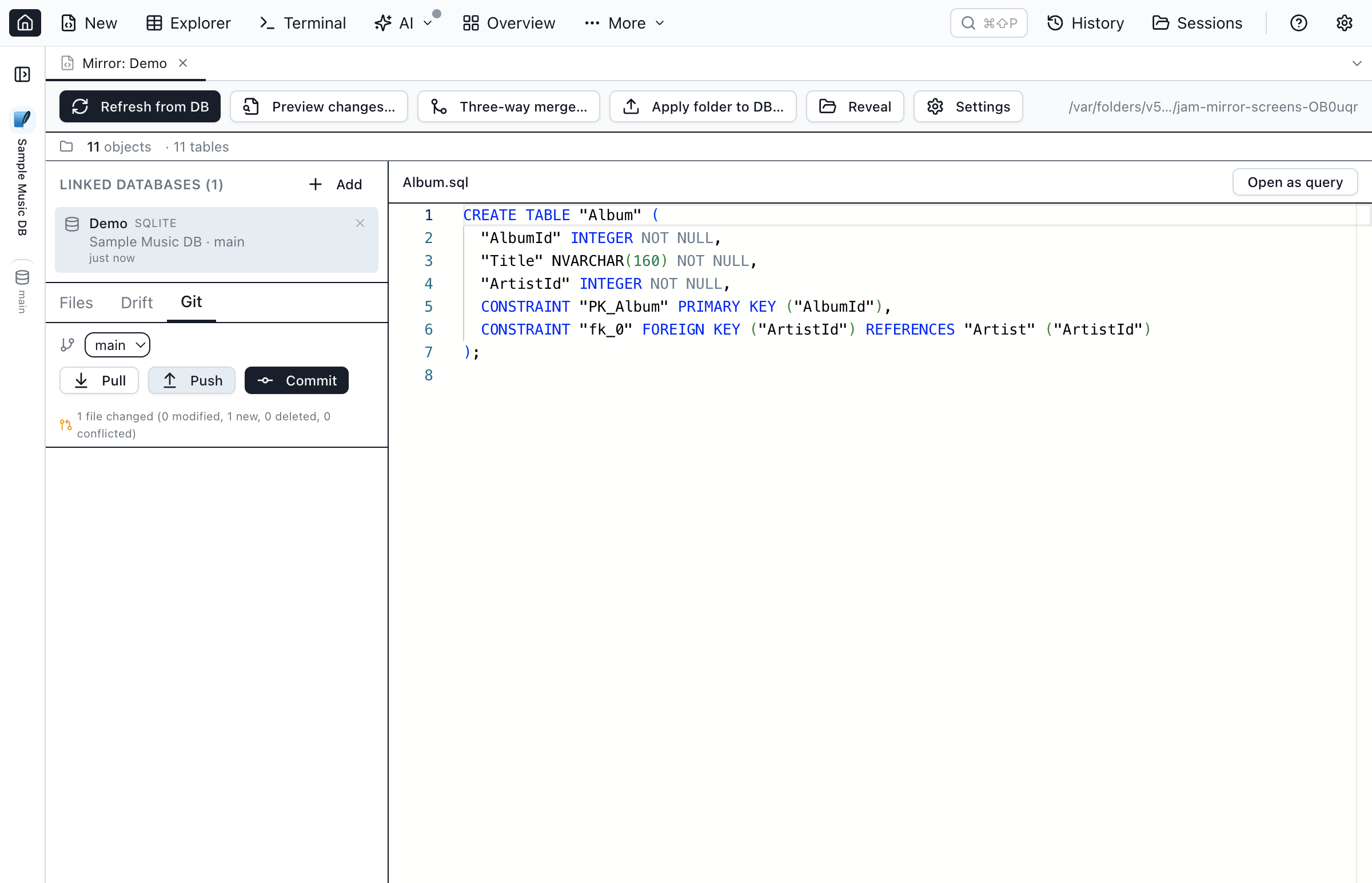
Git integration
The Git panel inside the Database Blueprint tab gives you the basics without leaving Jam:
- Status — branch + tracking, ahead/behind counts, and per-category counts (modified, new, deleted, conflicted).
- Initialize git for new blueprint folders that aren't yet repos.
- Commit with an auto-generated message keyed off changed sub-folders (e.g.
Refresh from DB: 2 tables, 1 view, 1 proc (Dev)). - Branch switch, pull, push.
- Merge-conflict resolution — when a pull leaves conflicted
.sqlfiles, the conflict dialog lists them, shows the raw file content with<<<<<<</=======/>>>>>>>markers in a read-only Monaco viewer, and provides Mark resolved per file (stages the file viagit add).
Personal mode limits
Database Blueprint is available in Personal mode for databases with up to 200 objects (tables + views + procedures + functions). When you hit that limit, Jam opens the Upgrade dialog so you can learn more about Pro — no raw error string. Pre-existing blueprints continue to read and display correctly in Personal mode; only the Create Database Blueprint and Refresh from DB actions are gated.
AI-managed blueprints (MCP tools & CLI)
AI agents (Claude Code, Cursor, Codex, or any MCP-compatible tool) can manage blueprints directly via eight blueprint_* MCP tools and the equivalent jam-sql blueprint CLI subcommands. All operations are gated by the same permission model as SQL writes — configure the level in Settings → AI Integrations → Permission Level.
Read operations
Available at permission level read-only or confirm (denied at block):
blueprint_list/jam-sql blueprint list— list registered blueprints with folder path, label, linked-DB count, and engine.blueprint_get/jam-sql blueprint get --folder /path/to/bp— inspect full metadata, object counts, and on-disk drift for a specific blueprint.blueprint_preview/jam-sql blueprint preview --folder /path/to/bp— preview which files would change on the next refresh, without writing anything.
Mutating operations (folder or registry)
Write-gated: denied at block and read-only; requires user approval in the in-app dialog at confirm:
blueprint_attach/jam-sql blueprint attach --folder /path/to/cloned-bp— register an existing blueprint folder (e.g. aftergit clone).blueprint_create/jam-sql blueprint create --connection <id> --database MyDB --folder /path/to/empty --label Dev— materialize a database as a new blueprint in an empty folder.blueprint_refresh/jam-sql blueprint refresh --folder /path/to/bp— re-emit DDL and data sidecars from the linked database into the folder.
DB-mutating operations (modify the live database)
Write-gated at confirm only, with the in-app approval dialog showing the exact generated SQL before execution. Jam SQL Studio must be open and focused; a 60-second timeout auto-denies:
blueprint_apply_schema/jam-sql blueprint apply-schema --folder /path/to/bp— runs a headless folder→DB schema compare, generates the sync SQL, shows it for approval, and executes it.blueprint_sync_data/jam-sql blueprint sync-data --folder /path/to/bp— for each blueprint-data table, runs a folder→DB row compare, builds a two-phase script (deletes then upserts), shows it for approval, and executes.
For more details on the full AI integration setup, see AI Integrations & MCP.
Frequently asked questions
What is Database Blueprint?
Database Blueprint is a Jam SQL Studio feature that materializes a database's full DDL as a folder of .sql files (one file per table, view, procedure, function, schema). The folder is kept in sync with the database — refresh from DB to pull the latest schema, preview pending changes, run a three-way merge, or apply local edits back to the database. Two-way sync covers tables, views, procedures, functions, and schema definitions: local edits to Tables/*.sql files (column / constraint / index changes) round-trip back to the database across SQL Server, PostgreSQL, MySQL, Oracle, and SQLite (SQLite supports add / drop column only, since it has no in-place ALTER). The folder can be tracked in Git and shared with teammates like any other source-controlled project.
Which database engines does Database Blueprint support?
Database Blueprint supports SQL Server, PostgreSQL, MySQL/MariaDB, Oracle, and SQLite. Blueprint folders can link to one or more databases of the same engine, with per-link MetaInfo (loose foreign keys, JSON column declarations, enum declarations) persisted alongside the schema.
How do I apply local edits back to the database?
Open the Database Blueprint tab and click Apply schema to DB. Jam reuses Schema Compare with the folder as the source and the linked database as the target, so you get a full diff, can choose which objects to apply, and review the generated DDL before executing. This covers tables, views, procedures, functions, and schema definitions — local edits to Tables/*.sql (column / constraint / index changes) round-trip back across SQL Server, PostgreSQL, MySQL, Oracle, and SQLite (SQLite supports add / drop column only).
Does Database Blueprint integrate with Git?
Yes. The Git panel inside the Database Blueprint tab detects whether the folder is a git repository (or offers to initialize one), shows status (modified / new / deleted / conflicted files, ahead/behind counts), and provides commit, branch switch, pull, and push actions. Commit messages are auto-generated from the changed file set (e.g. 'Refresh from DB: 2 tables, 1 view (Dev)'). Merge conflicts are surfaced with a built-in Mark resolved button that stages the file (git add).
Is Database Blueprint available in the free Personal mode?
Database Blueprint is available in Personal mode for databases with up to 200 objects (tables + views + procedures + functions). Larger databases require Pro mode.
Related features
- Schema Compare — used internally by Apply schema to DB; also runs interactively for DB ↔ DB diffs.
- Loose Foreign Keys — declared in MetaInfo and persisted in
jamsql-meta-<label>.jsonalongside the blueprint. - JSON Columns and Enum Columns — also persisted per-link in MetaInfo.
How it compares to other schema-version-control workflows
If you're coming from another tool's take on "database as code," see how Database Blueprint's folder-of-.sql-files plus built-in Git panel stacks up:
- DBeaver Version Control — DBeaver's Git integration tracks a project's scripts and diagrams, not the live schema itself.
- DataGrip Version Control — DataGrip pairs a general Git plugin with a DDL data source for schema-as-files.
- Navicat Version Control — Navicat generates SQL scripts you commit yourself in an external Git client.
- Azure Data Studio SQL Database Projects — the SDK-style
.sqlproj/dacpac approach, SQL Server-only.